Natural Language Processing is a part of the curriculum of our Computer Science courses at Ambalika Institute of Management and Technology, one of the best engineering colleges in Lucknow.
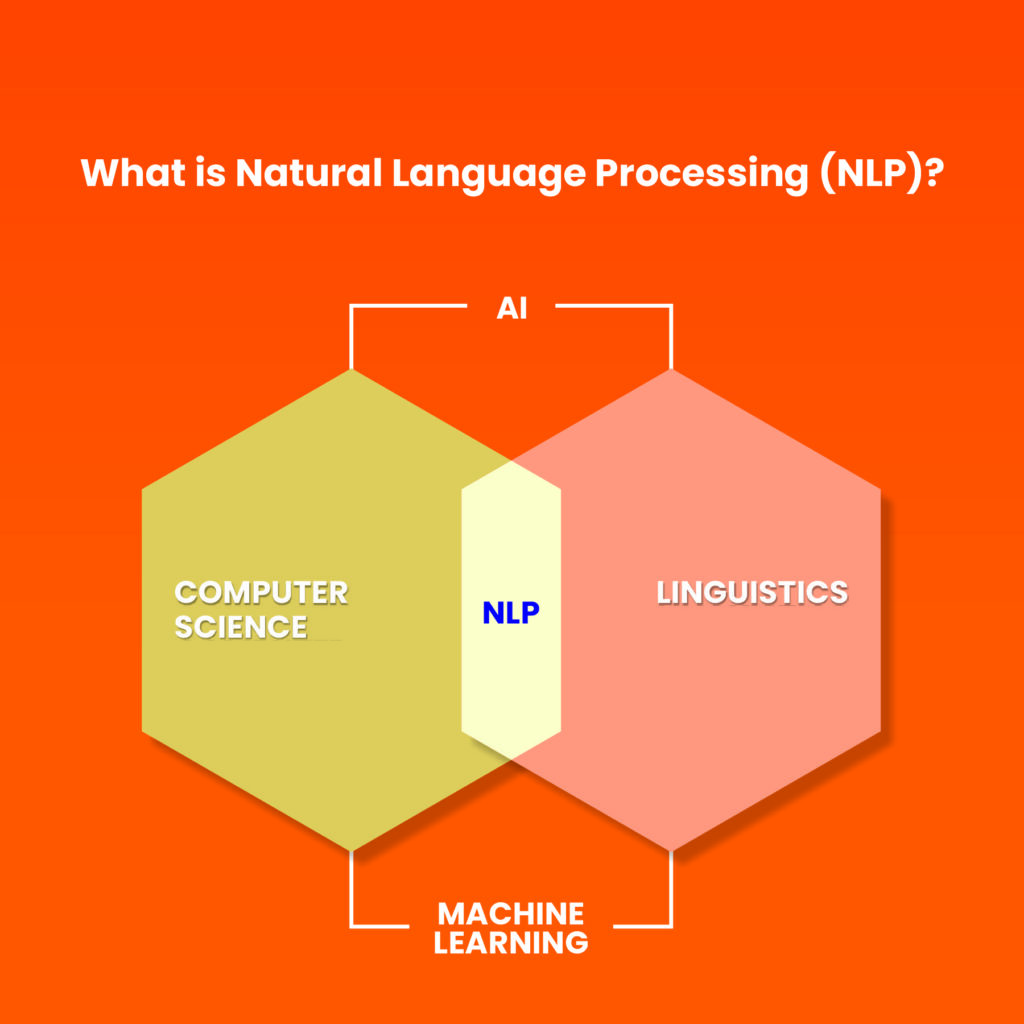
Natural Language Processing (NLP) is an application of Artificial Intelligence (AI). Human language is complex and has many nuances, but we learn native languages instinctively and spontaneously through childhood and adolescence. How do we get computers to understand human language, without them having gone through this natural process, especially considering that there are many informal rules in human languages and computers do not innately have experience of intent or context? This is where NLP comes in. NLP is how a machine derives meaning from a language it does not natively understand, including interpreting context and intent through analysis.
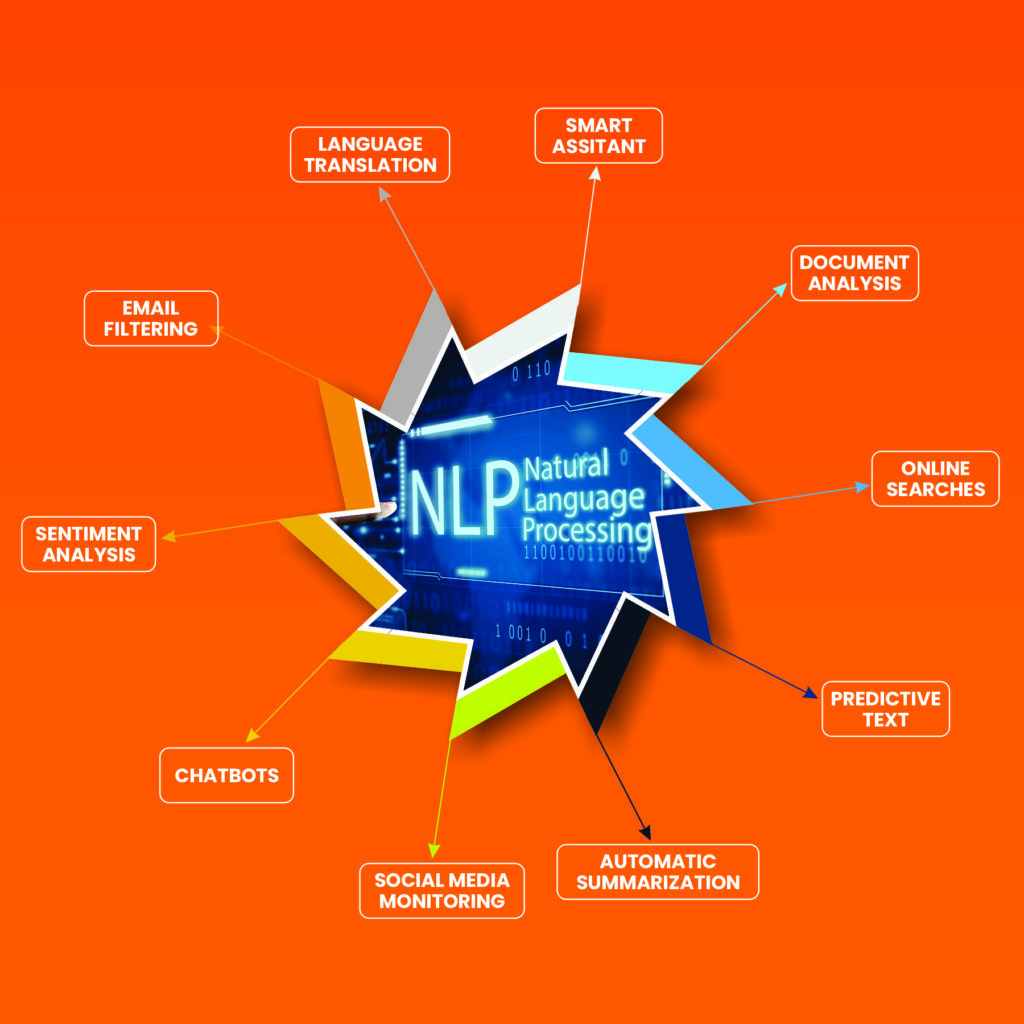
NLP has reduced human dependency on computing systems to perform repetitive tasks. We can see examples of this in action in our everyday lives when we use email spam filters, autocorrect and predictive text, language translation software, Chatbots and smart assistants like Alexa, to name a few among hundreds of applications of NLP. Email spam filters were one of the first applications of Natural Language Processing. They employed the identification of certain words and phrases to indicate spam. Simple filters have now given way to automatic email classifications, such as that done by Gmail when it categorises emails into Social, Promotions or Primary.
Applications of Natural Language Processing
The 4 stages in Natural Language Processing are:

- Sentence Segmentation: One of the core procedures in natural language processing is sentence segmentation. It entails segmenting a given text into discrete sentences, a process with applications in many settings. Since the words and sentences detected at this stage are the fundamental units transmitted to future processing stages like morphological analyzers, part-of-speech taggers, parsers, and information retrieval systems, text segmentation is a frequently disregarded yet crucial component of any NLP system.
- Word Tokenisation: Finding the word boundaries—the places where one word ends and another begins—is the first step in the process of tokenization, which divides a text’s character sequence. The words thus recognized are sometimes called tokens in the context of computer linguistics.
- Parts of Speech: Assigning a grammatical category to each word in a text—such as nouns, verbs, adjectives, and adverbs—is a fundamental task in Natural Language Processing (NLP). This method enables computers to analyze and interpret human language more correctly by improving their grasp of phrase structure and semantics.
- Parsing:Parsing is the process of dissecting a sentence to determine its structure, meaning, and constituents. In other words, it involves identifying the components of the input sentence, articulating their relationships, and uncovering its structure.
So what is the future for NLP?
Natural Language Processing (NLP) is a rapidly developing field with wide-ranging applications in several industrial areas. The rapid rise in popularity of AI-driven technologies within certain areas can be ascribed to its exponential expansion.
Even while machine-generated solutions are advancing quickly, there are situations where producing uniquely workable answers requires thinking like a human. We enable smooth machine-to-machine communication by incorporating natural language processing (NLP) into AI frameworks. This allows for input provision and decision-making processes that are highly similar to human cognition.
Additionally, this encourages amicable machine-human contact, which facilitates cooperative problem-solving and the extraction of amazing results. Predictions indicate that NLP applications will play a significant role in important industries like healthcare in the near future.